
Author: Fikret OTTEKİN, Software Consultant / Advisor to CEO

This blog entry is mostly for software developers and project managers.
Mediocre-quality software is available anywhere and everywhere. We have all encountered it using our desktops, smart phones, running applications from the cloud, and suffered various amounts of pain both as user and developer. Dealing with software, I had done my share of losing and causing loss, and I had done it my way.
I have been wondering about how to develop “good software” for many years; but what is “good software” anyways? Software quality is a broad topic, including functional correctness and structural aspects, which are reliability, efficiency, maintainability and security. Definitions of these conventional terms, as well as the following unconventional remarks about software quality are all available in Wikipedia:
- “The difficulty in defining quality is to translate future needs of the user into measurable characteristics.”
- “A product’s quality is a function of how much it changes the world for the better” (see, if you please, the 2005 movie “Kingdom of Heaven” where a blacksmith makes a similar statement in the 12th century: “What man is a man, who doesn’t make the World a better place?”).
Subject is broad, for sure. Yet, I still want to make an attempt to define a couple of tips for software quality, which would hopefully help somebody, somewhere build better software.
Limit features expected from the software
Customers maybe unable to estimate the computational complexity that should be achieved by the developers to implement the feature they request. It is the joint responsibility of the developers and the manager to sort out what is possible and what is not, for everyone’s sake. Developers may like being challenged too, whereas all projects have to be concluded using finite time and resources. And reminding that to the customer is just fine. In order to make sure your project’s complexity remains within your reach, you should keep communicating with the customer. Present realistic details until the development cost and risks involved in seeking the requested features are appreciated.
Design well-defined interfaces and validate inputs
A man’s home is his castle and so is a man’s software. Your interfaces are entries to your castle. Make sure they are well-guarded.
There are two categories of input:
- Input you are supposed to process
- ELSE (Input you are not supposed to process, input you shouldn’t process, input crafted to fool you, trick you, input coming in insane amounts, etc.)
In simplest terms, input validation is deciding whether an input is appropriate or not. That is basically done by checking both the syntactic and semantic correctness of data.
You have to pay attention to the branches covering invalid data; some sort of processing may still be required while eliminating them. In some cases, an invalid input may be simply ignored. But there may be many other cases where you need to give an alarm, push a message to the console, write a log, free a memory block, and so on.
SQL Injection and Cross-Site Scripting have been the oldest tricks used by attackers to exploit applications which fail to validate input data properly. Although these techniques and their countermeasures are known for a long, long time, cracks keep reopening on the walls and damage is still being done by attackers. This is due to poor software maintenance practices and poor software architecture.
Input validation requires thoroughness. First step of input validation is interface documentation, which would cover all interfaces and criteria to differentiate valid/invalid inputs. That’s your homework. Interfaces of an application would probably include the user interface, the operating system interface, the database interface, the network interface, and even the configuration file you read when you boot (Figure 1).
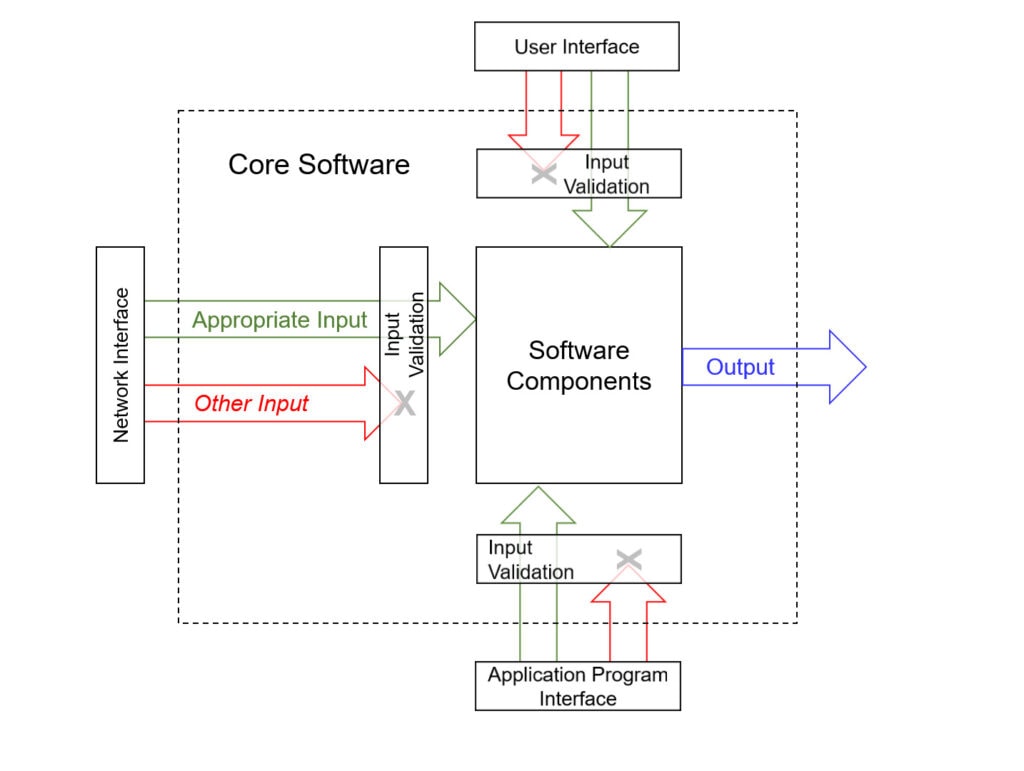
Figure 1 – Input data validation
Nadine Gordimer, recipient of the 1991 Nobel Prize in Literature, had said, “Writing is a voyage of discovery”. That statement is accurate in software engineering as well as it is in literature! Interface documentation will define the boundaries of both your software and your responsibility. That will protect you from misery in run-time; hence it is definitely worth your time and effort. It is difficult until you get started. Once you get started, it is great.
Input validation is the foundation of security as well as reliability.
It may be useful to note the difference between validation and verification, which becomes clear the moment these terms are expressed in their longer forms: “Input data validation” and “software verification”. Input data validation is a software feature implemented by developers to check the correctness of input data, while software verification is the activity conducted by testers to check the correct implementation of all software requirements, including input data validation.
Isolate interfaces from the platform if porting is on the horizon
If the probability of porting your code to a different platform seems likely, it may be worth isolating the Operating System and user interfaces from core modules, employing adaptation layers supporting generic interfaces. When the need arises to port your software to another platform, only the adaptation layers converting generic interfaces to platform-specific interfaces need to be rewritten.
That helps maintainability.
Any kind of input that can reach your software will reach your software. Which means, “All sorts of things roaming the operational environment that are not actively filtered out will knock your door”. Because of that, porting your software to a new platform or environment could have interesting consequences: Be prepared for input you haven’t met in the past.
Divide and conquer business logic
After due implementation of the first two steps, implementing the “business logic”, which is the core of your software, should be possible.
I had met an F-16 pilot on a bus journey from Ankara to Istanbul back in 1990, who complained that his name was being logged as “Mert” every time he was asked, although his name was actually “Mart”. “Simple tasks should be executed perfectly”, he was repeatedly saying, which raised the question, “What about the complex tasks?”. In other words, “How could complex tasks be executed perfectly?” He had answered that no task was complex, but I don’t agree with that. My own answer to that question is, “A complex task may be executed, perfectly or not, after being broken into simpler tasks”. Then, “breaking the complex task to simple tasks correctly and consistently” becomes the main task, which may be quite complex. Tackling that task is the job of the software architect – a persona who is expected to be a fountain of wisdom and dedication.
If studied (or broken into) sufficiently, your software requirements could be implemented on a reasonable number of clearly defined software components (Figure 2). Each component should emerge as a finite state machine consisting of a number of states and inputs.
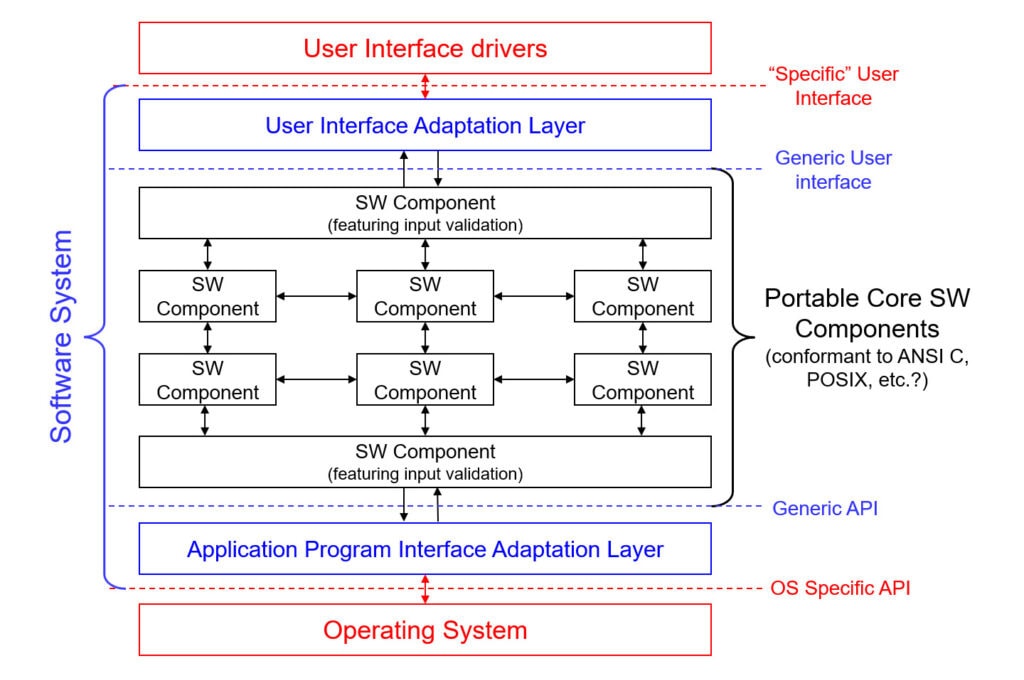
Figure 2 – Software system at the end of high-level design phase
Simple as it is, the state transition table is a gem of data presentation format for finite state machines. You may use it to make sure you have decided what to do about every single State+Input combination, including how invalid inputs should be processed. For example, see in Figure 3, the preliminary State Transition Table for Border Gateway Protocol-4 generated according to information available in RFC 4271 and RFC 4724 standards.

Figure 3 – Border Gateway Protocol (BGP-4) State Transition Table
State transition tables are the foundations of implementational correctness. They would also help define the functional tests to be executed on software components, providing the basis for verification.
Monitor your system in run-time, and do it with style
A software may generate the correct output for every input there is, yet exhibit insufficient throughput in run-time, if it keeps running at all (attribute of running correctly for extended periods is called “reliability”).
Another software may generate the correct output for every darned input provided, yet generate a false-alarm once in a couple of weeks.
Yet another software may run O.K. on a server on the Demilitarized Zone, but crash occasionally when installed on a server on the Intranet.
In order to get a clue about what is going on in the core software, developers usually print log messages to the console. Adding log messages to the code sometimes alter the run-time characteristics of the software and generate problems of their own, further puzzling the developers. The console usually gets out of hand due to the load of log messages, yet still helps developers survive on many occasions.
Including a permanent run-time monitoring facility in the system design right from the beginning may both improve monitoring capability and minimize the development cost. For convenience, and to convey a sense of quality, go ahead and present the parameters obtained from the development platform on a custom dashboard (Figure 4).
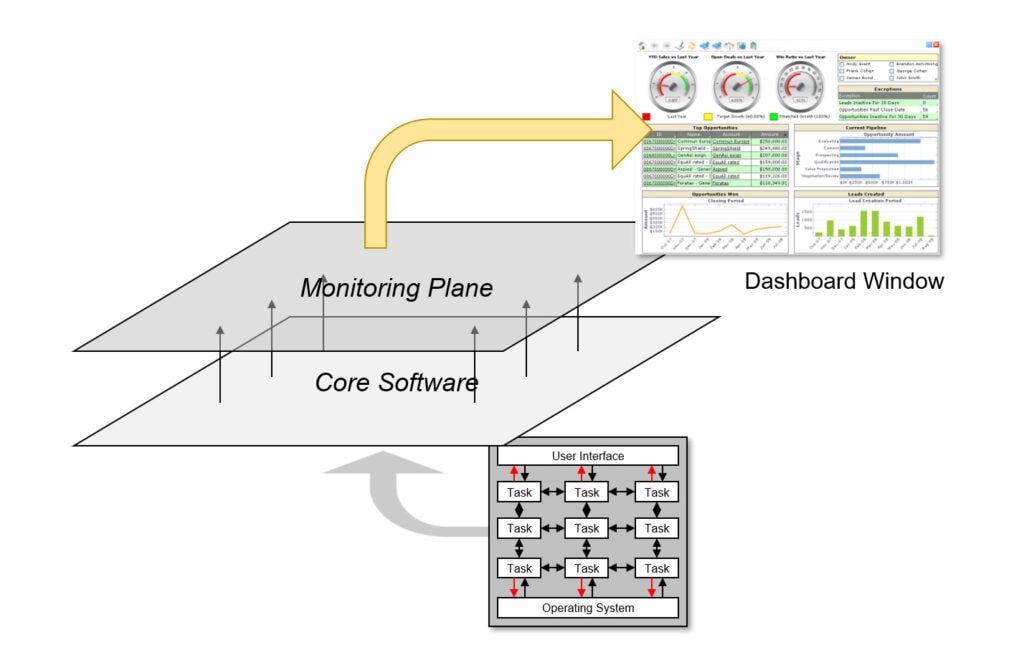
Figure 4 – Monitoring software with a dashboard
It is up to you to decide what to monitor. For instance, parameters critical to your design such as the length of a queue on a critical path and its high-tide and low-tide values may be monitored. Hence, insight about the run-time characteristics of your platform and input vectors challenging your software may be obtained.
Run-time monitoring capability can save you from mishaps such as datagrams getting lost among your software components, or provide clues that would help you improve your software’s efficiency and reliability.
Simplicity is both a journey and a destination
Simplicity in design helps achieve multiple quality attributes.
RFC 1958, “Architectural Principles of the Internet” makes the following advice: “Keep it simple. When in doubt during design, choose the simplest solution.”
Mentors of computer science have also praised simplicity in design.
As an extension to the recommendation of RFC 1958, I would like to quote the Dutch computer scientist Andrew S. Tanenbaum, the author of “Computer Networks”, who has given the following advice to his readers: “If there are several ways of doing the same thing, choose one. Having two or more ways to do the same thing is looking for trouble.” Hence, simplicity should include implementing a feature in a single function/class and referencing that function where needed. Functions/classes should be unified whenever possible. That would let you know which part of the code to investigate when an issue arises. What’s more, you will have to make a correction/improvement only once, if you need to. That would improve maintainability.
I suppose that the dual of this principle in computer hardware design is RISC (Reduced Instruction Set Computers) where, instead of being built from scratch, complex features are implemented reusing simple blocks whose correctness and performance have been verified.
Another Dutch computer scientist, Edsger W. Dijkstra had said, “Simplicity is prerequisite for reliability”, which rather means, “Forget about reliability if you haven’t achieved simplicity”. Hence, the design phase is not completed until both the overall system and the components look simple and straightforward.
Simplicity is a pinnacle, a sign of maturity, but it is not achieved easily. Dijkstra has stated that, “Simplicity is a great virtue but it requires hard work to achieve it and education to appreciate it. And to make matters worse, complexity sells better.” That’s probably why simplicity is neither demanded nor supplied by many. In the mean time, demand for complexity keeps creating pressure on the developers and possibly the quality of the end products.
Suggestions about documenting the software interfaces and components and simplifying the design do actually mean homework. Doing that homework is the process towards quality and there is no bypassing it. But that process should be simple as well: Break your homework into pieces until each piece is achievable and enjoyable!



